
I'm an AI researcher focused on improving and scaling large language models. My work involves developing novel techniques for analyzing and training LLMs to make them more capable and reliable.
I've been programming since I was 12, and got a formal education in AI by studying machine learning at the University of California San Diego. I also have a background as CEO of an edtech company.
I usually fluctuate between being deep into engineering and research, and very close to the product.
BenchHub.ai
BenchHub.ai is a website designed to help people visualize famous AI benchmarks, showing what they actually look like, their differences, and potential problems. It includes benchmarks such as MATH, Humanity's Last Exam, ARC-AGI, AIME, and GPQA. BenchHub.ai presents these benchmarks in intuitive visual formats, making them easy for humans to quickly understand. Additionally, it shows benchmarks exactly as Large Language Models (LLMs) would see them, offering side-by-side comparisons between human-friendly views and model-oriented representations.
ModelPeek.ai
ModelPeek.ai is a visualization tool that reveals how Large Language Models memorize and process information. It features a novel detector that identifies memorized content by analyzing the model's internal patterns, along with detailed visualizations of attention patterns, loss metrics, and token predictions. The tool helps researchers and practitioners understand model behavior, evaluate training quality, and distinguish between genuine comprehension and memorization in LLMs.
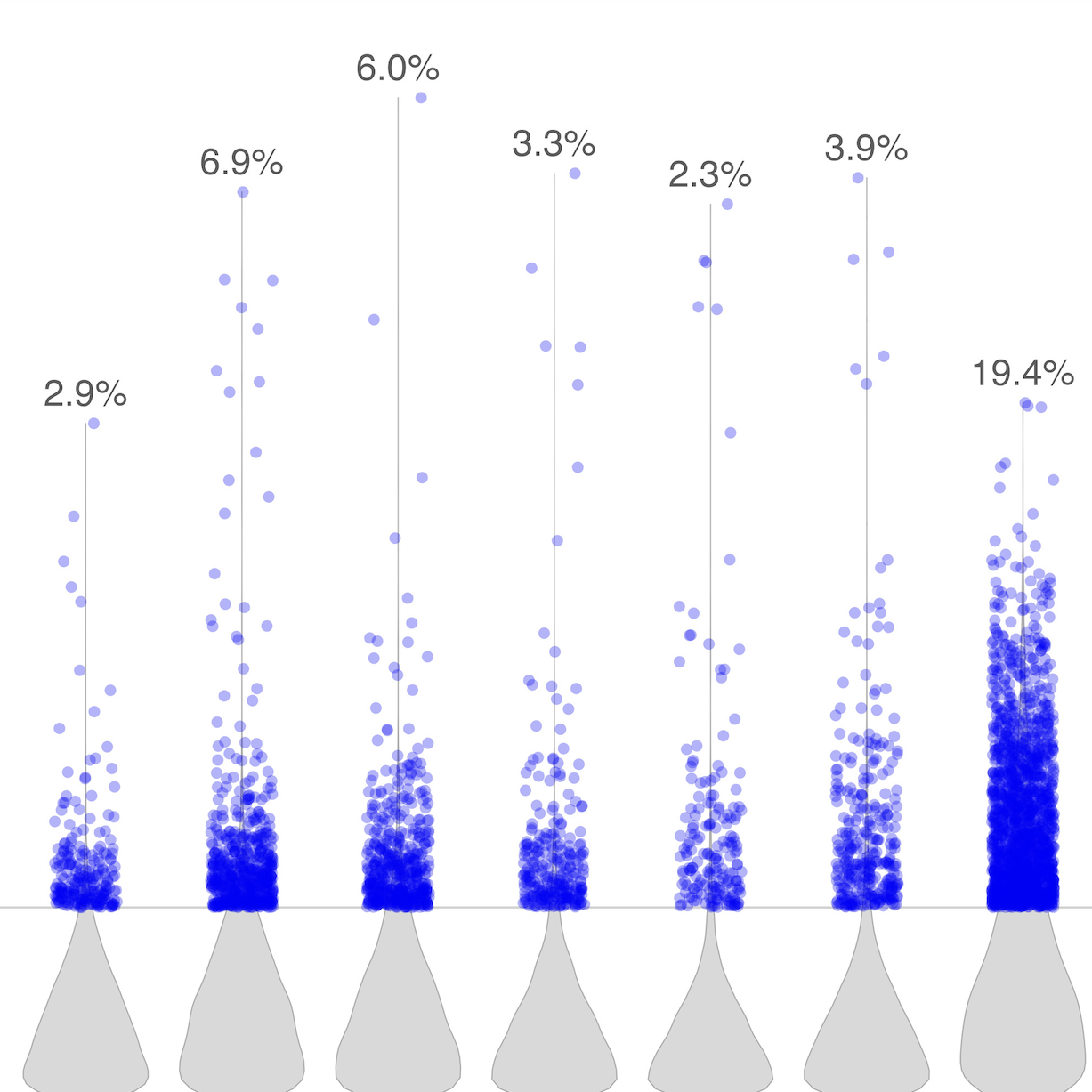
Detecting Memorization in Large Language Models
The paper presents a method for detecting memorization in Large Language Models through neuron activation pattern analysis. Using classification probes trained on these patterns, we achieve high accuracy in identifying memorized content and can control model behavior. The approach extends to other mechanisms like repetition, providing tools for improving model evaluation, training, and interpretability.